Дорогие коллеги и пользователи корпуса!
Бета-версия ГИКРЯ 2.0 доступна на платформе НКРЯ! В нее вошли тексты социальной сети «ВКонтакте» с 2007 по начало 2022 г. общим объемом 11,3 млрд слов.
Морфологическая разметка ГИКРЯ 2.0 выполнена с помощью интегрального морфосинтаксического парсера (автор — Даниил Анастасьев) с доработанной лемматизацией (подробнее о наших доработках можно почитать здесь). Полученная разметка в формате Universal Dependencies затем преобразована в морфологический стандарт НКРЯ.
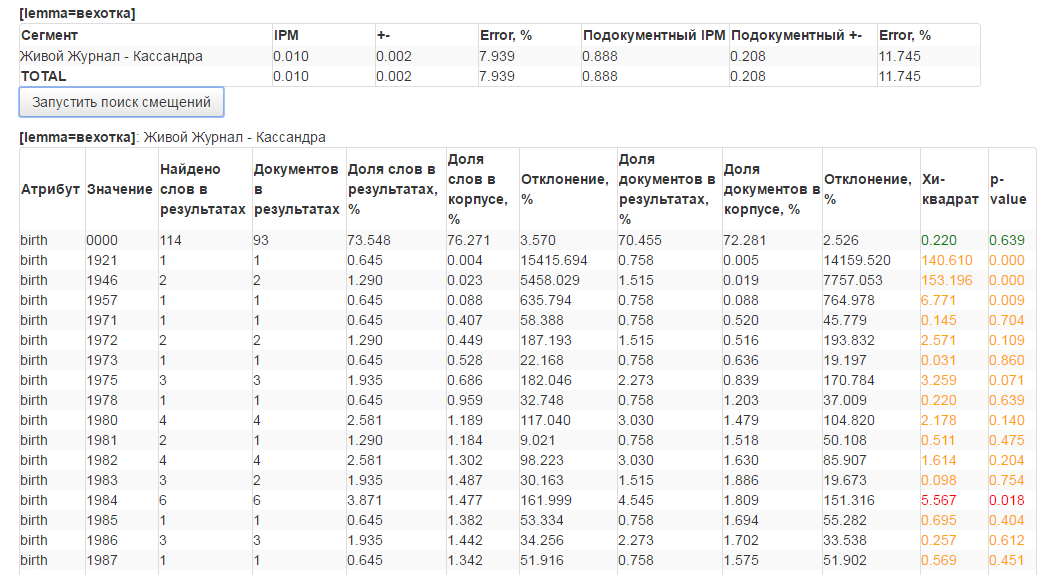
Метатекстовая разметка включает год и месяц написания текста и его тип (пост или комментарий), год рождения, пол и регион автора, извлеченные из его профиля в социальной сети.
Интерфейс НКРЯ позволяет выполнять поиск по лемме, словоформе, и грамматическим признакам (в т.ч. с использованием регулярных выражений), задавать подкорпус по метатекстовым признакам, получать выдачу в форматах Конкорданс и KWIC с сортировкой по заданному параметру, строить графики по времени публикации текста и получать статистику по социолингвистическим параметрам.
Будем рады ответить на ваши вопросы по ГИКРЯ 2.0: пишите нам по адресу info@ruscorpora.ru. Если вы обнаружили ошибку в системе НКРЯ, сообщите об этом через форму.