В данном разделе описывается процедура отбора и технологическая цепочка обработки текста в ГИКРЯ, а также смежные проекты.
Отбор текстов:
Для сбора и очистки текстов используется программа Nutch. Для наших целей её пришлось доработать, вот основные моменты: для любых веб-страниц в Apache Nutch использовались общие алгоритмы выделения ссылок и отделения служебной информации от пользовательского контента. Не было возможности присваивать метки контенту, представляющему собой метаинформацию, связанную с текстом – такому, как интернет-псевдоним автора, возраст, пол, место рождения, получения среднего образования и настоящего места проживания. Мы научили программу выделять все это на тех страницах сайтов, которые сделаны по одному и тому же шаблону.
Далее отобранные тексты очищаются от «мусора» (служебной информации, рекламы, динамически формируемых новостных полос, спама, автоматически сгенерированного текста). В ГИКРЯ также проводится дедубликация текстов по алгоритму «3+5».
Если Вы являетесь правообладателем какого-либо текста, который по результатам автоматического краулинга находится в нашем корпусе, и это представляет проблему — напишите нам. Наш проект — некоммерческий, и тексты в корпусе являются доступными только для поиска.
Токенизация
Токенизация в корпусе осуществляется при помощи токенизатора razdel, доработанного для нужд ГИКРЯ. Отдельными токенами считаются все знаки препинания, а также все сочетания с дефисами, где каждая часть имеет часть речи. Знаки препинания могут образовывать кластеры.
Морфоразметка версии 1.0
В ГИКРЯ 1.0 мы используем свободно распространяемую программу TnT-Russian (автор – Сергей Шаров), которая отвечает за морфологическую разметку и лемматизацию с некоторыми внесенными нами модификациями. При разметке используется словарь, созданный при помощи объединения возможностей TnT-Russian и mystem. Объем словаря – более 7 млн словоформ.
Разметка на настоящий момент соответствует широко используемой кодировке MULTEXT-East for Russian.
В корпусе осуществляется лемматизация на базе упомянутых выше модифицированных словарей TnT-Russian, а несловарные слова проходят модуль cstlemma, работающий на базе русских суффиксов.
Пример морфологический разметки в корпусе:
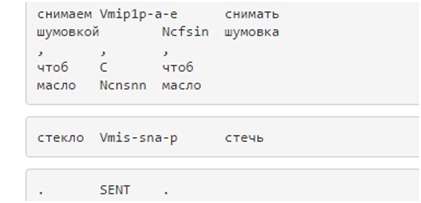
Морфоразметка версии 2.0
В новой версии мы используем Интегральный морфосинтаксический парсер (автор — Даниил Анастасьев) с доработанной лемматизацией (подробнее о наших доработках можно почитать здесь). Полученная разметка в формате Universal Dependencies затем преобразуется в морфологический стандарт НКРЯ.
Синтаксическая разметка версии 2.0
Интегральный морфосинтаксический парсер формирует не только морфологическую, но и синтаксическую разметку в формате Universal Dependencies. В наших планах организовать её визуализацию и поиск по ней.
Семантическая разметка версии 2.0
На данный момент работа над автоматической семантической разметкой только начинается, однако мы планируем не только разметить корпус, но и предоставить возможность пользоваться семантическими скетчами.
Жанровая разметка версии 2.0
По состоянию на конец 2021 года автоматическая разметка в категориях FTD (автор этой классификации — Сергей Шаров) есть в сегменте «Живой Журнал».
Метатекстовая разметка
ГИКРЯ богат метатекстовой разметкой: для каждого текста из соцсетей хранятся время и место его написания, URL, интернет-жанр (блог, новости и т.д.), а также год, место рождения автора, пол автора. Благодаря интерфейсу ГИКРЯ, при поиске удобно задавать любые настройки из вышеперечисленных, а также сортировать уже полученные результаты по данным признакам.
На материале корпуса решаются актуальные задачи современной прикладной лингвистики: автоматическая региональная, жанровая, гендерная, возрастная классификация текстов, динамическая дедубликация (то есть дедубликация поисковой выдачи, а не корпуса целиком), автоматическое исправление опечаток, улучшение автоматического снятия.
Индексирование
Чтобы обеспечить прямой доступ к текстам, должны применяться язык запросов и методы быстрого поиска. Индексирование таких больших корпусов – это сама по себе большая научная задача. Чтобы обеспечить быстрый поиск по текстам с возможностью задать в качестве признаков грамматические категории, точные формы слов или леммы, в ГИКРЯ мы реализуем собственный поисковый индекс.
Лингвистический поиск в ГИКРЯ можно осуществлять двумя способами: через поисковую строку, набирая вручную требования к поисковым позициям или используя для этих же целей конструктор запросов. Например, чтобы искать имена собственные женского рода, можно набрать выражение на corpus query language [pos=»Npf….»] самому или просто расставить флажки:
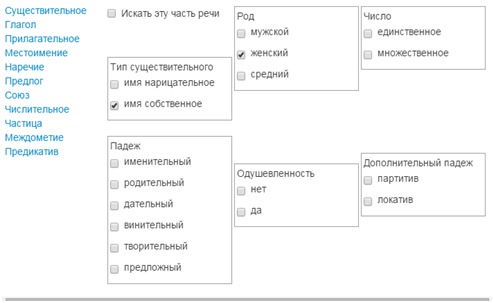
Объем корпуса
В настоящий момент в ГИКРЯ представлены крупнейшие ресурсы social media – ВКонтакте, ЖЖ, а также материалы новостных сайтов и Журнальный Зал. Эти ресурсы постоянно докачиваются, ведется также скачивание некоторых других.
Состав ГИКРЯ 1.0 на 2021 год:
- Журнальный Зал: 313 млн слов, 56547 документов
- Новости (Риа, Регнум, Лента ру, Росбалт): 851 млн слов, 2964897 документов
- Живой Журнал: 8110 млн слов, 73229158 документов
- ВКонтакте: 9820 млн слов, 193770717 документов
Состав ГИКРЯ 2.0 на 2021 год:
- ВКонтакте: 5115 млн слов, 191 млн документов
- Журнальный Зал: 320 млн слов, 73 тыс. документов
- Живой Журнал: 15987 млн слов, 354 млн документов
Возможности корпуса
ГИКРЯ – корпус, который соединяет полноту и объем данных интернета и точность анализа, которая свойственна корпусам, собранным вручную. Мы решили, что для того, чтобы выйти на новый уровень достоверности частот изучаемых явлений, нам стоит поставить себе цель собрать новый дифференциально полный корпус размером не меньше 50 млрд. слов. Отличительной особенностью задачи сбора сверхбольшого корпуса является необходимость использования полностью автоматических методов сбора, очистки и лингвистической разметки корпуса. Этот проект связан с разными областями компьютерной лингвистики – можно испытывать и усовершенствовать разные системы автоматической разметки, автоматической классификации текстов, задействовать машинное обучение. Так что не только результат, но и сам процесс работы, как мы надеемся, принесет много пользы научному сообществу.
Зарубежные ученые тоже пытаются делать такие текстовые коллекции, но они мало размечены, и можно сказать, что эта отрасль только начала развиваться, а правила, по которым нужно собирать тексты, только формируются. Самые большие из существующих корпусов – это Британский национальный корпус (около 1 млрд. слов), Национальный корпус русского языка (500 млн. слов) и корпуса и Araneum Russicum (в этих корпусах содержится 15 миллиардов слов, они собраны из интернет-источников, но не содержат подробных метаданных о текстах). Несмотря на, казалось бы, внушительный размер, для серьезных научных целей эти корпуса вряд ли годятся, так как слишком малы и не содержат нужной метаинформации – зачастую лингвист не может правильно интерпретировать результаты исследования, так как остается неизвестным, какие тексты сформировали область поиска. Также в них нет критической массы текстов конкретных типов, достаточной, например, чтобы говорить о частоте, приемлемости или особенности употребления того или иного слова или языковой конструкции.
Поэтому-то для лингвистов и привлекателен интернет-корпус. ГИКРЯ дает лингвистам возможность использовать материал из интернета:
- Размеченный лингвистически
- Дедублицированный
- Отфильтрованный от спама
- Со сведенной на нет структурной неоднородностью страниц, но с сохраненной априорной разметкой пользователей интернета
- Подготовленный и индексированный специально для лингвистического анализа
Также корпус предоставляет обширный функционал для статистических исследований: пользователю доступны частоты запроса, ускоренный вариант поиска для получения только частот, а также разрабатывается функционал для установки пользовательского доверительного интервала при поиске.
Наши уникальные функции:
- Почта запросов: возможность пересылки запросов другим пользователям внутри интерфейса корпуса , с результатами и комментариями.
- Регулируемая длина контекста и тонкие пользовательские настройки дедубликации
Смежные проекты:
Работа над Генеральным Интернет-корпусом велась с учетом материалов и технологий, используемых в следующих проектах:
- Словарь «Языки русских городов»
- Форум «Городские диалекты»
Эти ресурсы ныне не функционируют, но мы восстанавливаем их функциональность в рамках проекта Языки Городов и Людей:
https://int.webcorpora.ru/reg2/index.php
- Интернет-корпус русского языка университета Лидс (Великобритания)
http://corpus.leeds.ac.uk/ruscorpora.html
- Национальный корпус Русского Языка
Мы выражаем искреннюю благодарность следующим организациям, оказавшим поддержку нашего проекта и внесшим существенный вклад в его развитие:
- Российский Государственный Гуманитарный университет http://rsuh.ru/
- Московский физико-технический институт (Государственный университет) http://mipt.ru/
- Университет «СколТех» http://www.skoltech.ru/
Поделитесь с коллегами!