Dear Colleagues!
We are pleased to present a new, open subcorpora of the General Internet Corpus of Russian – the segment of LiveJournal with automatically disambiguated homonymy, tagged in accordance with the new tagging format of GICR.
Here you can download the example of 50.000 tokens:

2 million wordforms are now available for downloading (please make a request at geekrya@gmail.com), and in the future we are going to increase this amount by using other GICR segments (VKontakte, Mail.Ru Blogs, News, Russian Magazine Hall).
We kindly invite developers and researchers to use this subcorpus to train their own parsers and improve existing systems.
- Material: 2 million wordforms from LiveJournal (users’ posts and comments)
- Tagging: Abbyy Compreno system
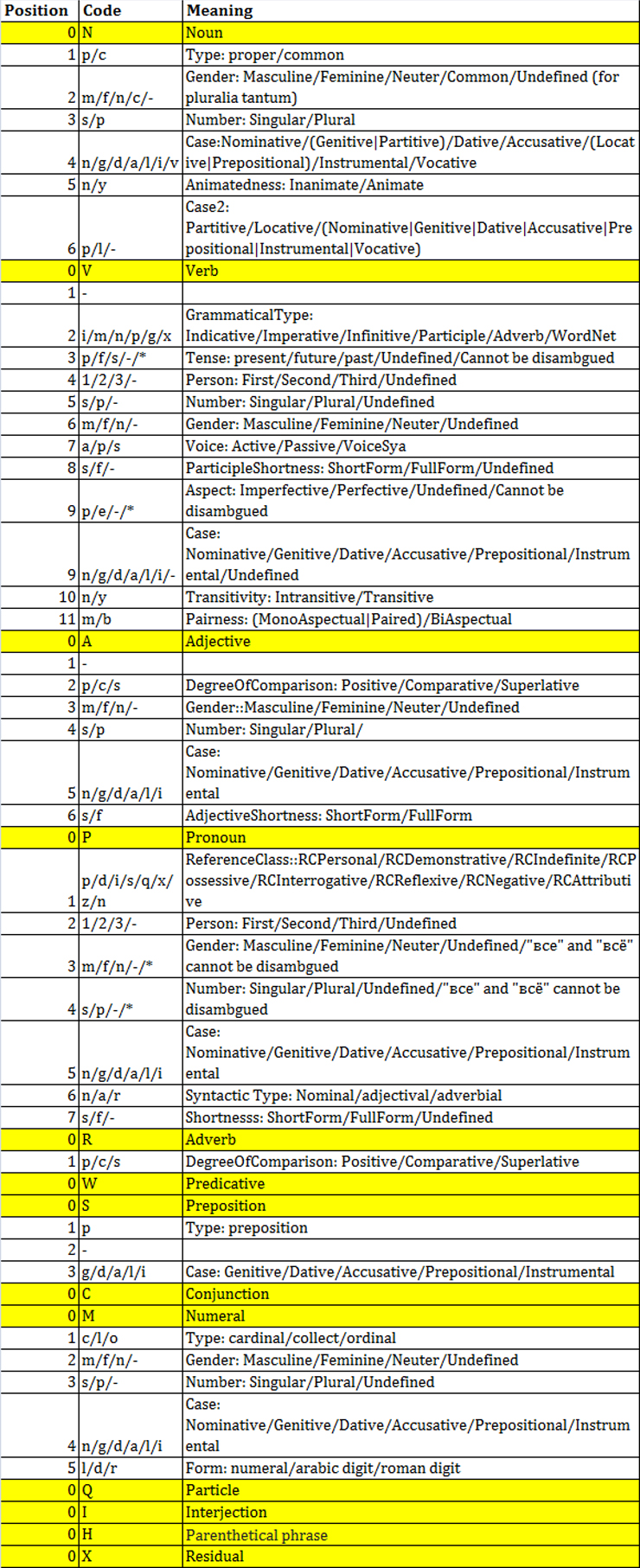
- Format: MSD-GICR, an updated version of the well-known tagset supplemented with previously unrealized categories.
Tagging example:
Если [если] C
хочешь [хотеть] V-ip2s-a-p-ym
тусить [тусить] V-n—-a-p-nm
—
туси [тусить] V-m-2s-a-p-nm
.
Если [если] C
хочешь [хотеть] V-ip2s-a-p-ym
бухнуть [бухнуть] V-n—-a-e-ym
—
бухни [бухнуть] V-m-2s-a-e-ym
New MSD-GICR tagset: